I wanted to see if I could predict house values in my hometown of Ann Arbor, Michigan, using data from Zillow.com. Though Zillow already has a feature like that called Zestimate, I wanted to make my own. I wanted to create a model that used different attributes of a house (square footage, number of bedrooms and bathrooms, etc.) to predict the sale price. This could also be used to see how much your house value goes up if you build an addition or install another bathroom in your house.
Collecting Data
Zillow has a nice API, however, to make a call (ie, get info from it) you must have the exact address of the listing. There is no way to search the API as you can on the website. Since my ‘target’ (what I’m trying to predict) is sale prices, I searched the website for recently sold houses, using selenium and beautiful soup to scrape the addresses of 1000 recently sold houses in Ann Arbor.
Now that I had a list of addresses, I could plug those into the API to get the data that I needed for my model.
Exploring the Data
After removing data with missing values I ended up with about 400 homes in my dataset.
Feature
Min
Max
Mean
Std Dev
House Size in Sq. Feet
560
10,969
1,876
1,008
Lot Size (sq ft)
871
3,484,800
40,900
187,434
Year Built
1885
2018
1964
26.5
Bedrooms
1
7
3.4
0.9
Bathrooms
1
9
2.5
1.2
Price
$20,000
$1,400,000
$382,910
$209,361
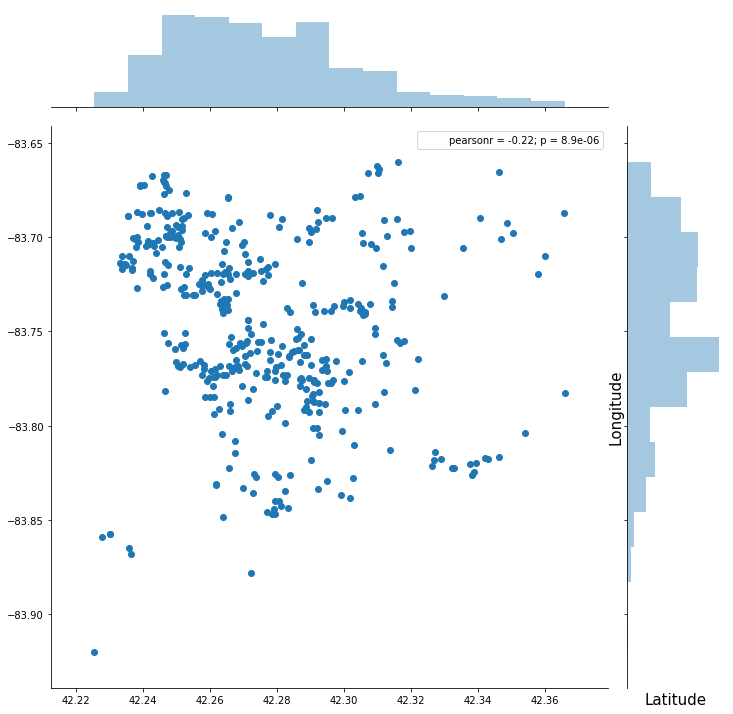
Plotting by each house’s location:
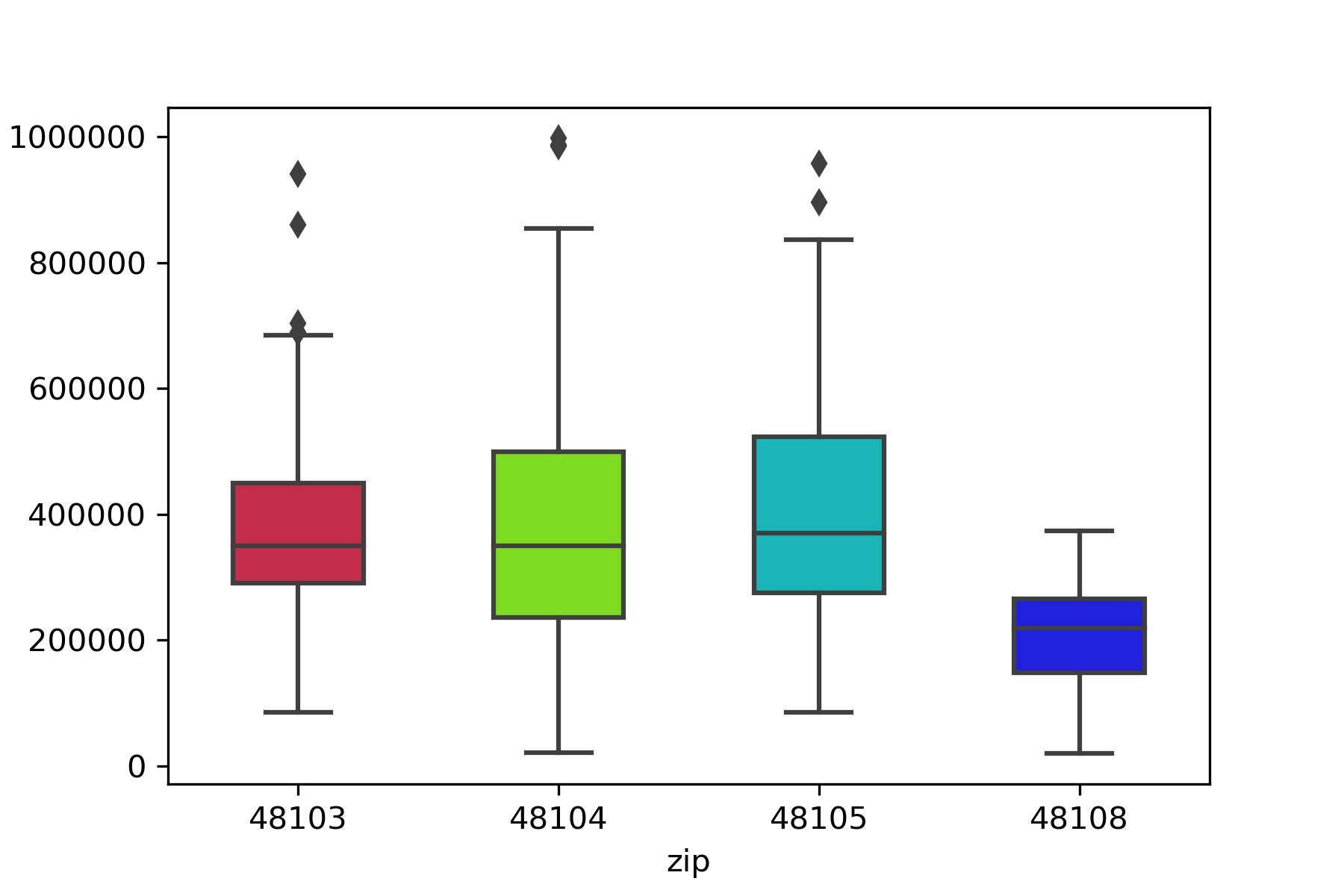
Plotting prices by zipcode:
I didn’t end up using zipcode or geographic location in my model. long and lat were not predictive, and while zipcode was a little bit, it didn’t make sense to me to use such arbitrary boundaries. (If I were doing more than one city it would make more sense to use.)
Feature Engineering
I applied a standard scaler to all of my features, which transforms the variables so that the mean is 0 and the standard distribution is 1.
I explored using polynomial features as well as interactions, but those didn’t seem to improve my model much, so I decided to keep it simple and leave those out.
Model
The model that I choose to use is an ordinary least squares linear regression. To account for collinearity of variables (for example, you might expect number of bathrooms and bedrooms to rise as the overall sq footage rises), I used a method called Ridge Regularization. Ridge Regularization– or L2 regularization– puts a penalty on large coefficients (also known as Betas, β), without making the coefficients zero. L1 regularization tends to “zero-out” some coefficients in favor of others, I didn’t want that.
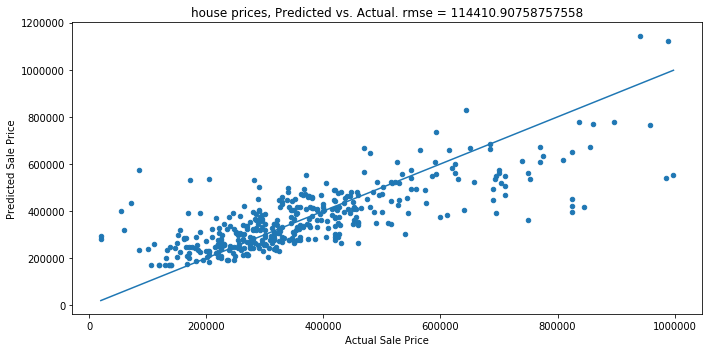
Here’s how my model did:
It had an r-squared value of 0.62, which means that my model accounts for 62% of the variation in home prices in Ann Arbor. I think with more features and more data points I can increase that even more.
Insights
According to my model, all else equal,
One additional:
correlates with an increase in value of:
Bedroom
$3,157
Bathroom
$26,818
House square foot
$49
Lot square foot
$0.30
Year older
$12
Most surprising to me was how valuable a bathroom is! $26k seems like a lot. I suspect that this is because more expensive homes tend to have more bathrooms, rather than one bathroom being worth more than $25,000. If I can collect more features, I suspect that that number will go down.
Based on this model, here is the formula for computing a house price in Ann Arbor:
Price in dollars = 379,428 - 12.1x(year) +3,157x(#bedrooms) + 26,818x(#bathrooms) + 0.29x(lot size in sq ft.) + 49 x (house square footage)
Hi, I’m Nick, an aspiring data scientist, and I will be blogging about my experience at the Metis data science bootcamp in Chicago. In the first week, we downloaded, cleaned and analyzed NYC subway data to see what patterns can be found in the data.
NYC has made the turnstile data publicly available on the MTA website. Unfortunately, the data is not exactly clean or user friendly, you can see it is in a .txt csv (comma separated values) file. We quickly learned that a large part of data science work is making sure that the data is clean and in a usable format. I will show you how I did this using python and pandas. Pandas (from the term panel data) is a library for python that provides data structures and makes working with relational data easy.
Importing data from the web
First we need to import the data into a pandas dataframe. My partner and I wrote this function that takes the date (mm/dd/yyyy) and the number of weeks and returns a data frame:
defcombine_mta_data(start_date,number):'''enter date mm/dd/yy (must be a Saturday, check http://web.mta.info/developers/turnstile.html for reference)
and number of weeks (including starting date week)'''mod_date=pd.to_datetime(start_date)url='http://web.mta.info/developers/data/nyct/turnstile/turnstile_'+str(mod_date.strftime('%y%m%d'))+'.txt'df=pd.read_csv(url)foriinrange(number-1):mod_date+=pd.Timedelta(days=7)url='http://web.mta.info/developers/data/nyct/turnstile/turnstile_'+str(mod_date.strftime('%y%m%d'))+'.txt'df=pd.concat([df,pd.read_csv(url)],ignore_index=True)df.sort_values(by=['C/A','SCP','DATE'],inplace=True)df.reset_index(inplace=True,drop=True)returndf
Run the function with your desired start date and number of weeks, I used April 22 2017 and four weeks.
If you look at the columns in the data frame (using df.columns), you’ll notice that one of them has a lot of spaces in the name. We can easily remove this using the python function .strip(). While we’re at it, let’s remove any duplicate entries.
You might also notice that there are two separate columns for date and time of day. Let’s go ahead and combine those into one column, I named it ‘TIMESTAMP’ (make sure you import datetime first).
weekdays=['MON','TUE','WED','THU','FRI','SAT','SUN']df['DOF']=[weekdays[dt.datetime.strptime(dstring,'%m/%d/%Y').weekday()]fordstringindf.DATE.tolist()]# DOF = "day of week"
Another thing I noticed when scrolling through the data is that, while the data is usually reported in four-hour intervals, when those occur is not always uniform, and some turnstiles were reporting much more frequently. To solve this, we create another column with “bins” to put each row into, in four hour intervals. Thanks to Lauren Oldja for this idea.
bins=[-1,4,8,12,16,20,24]df['HOUR']=[r.hourforrindf.TIMESTAMP]#hour of daydf['hourbin']=pd.cut(df['HOUR'],bins)
We also recognized that numbers of entries in exits were cumulative counts, since we can see that they are in the millions and keep increasing. To get the counts for each interval, we can use the pandas function .diff().
For this we wrote another function, find_deltas, that creates two new columns from the differences in the entries and exits columns. Later we found that some of the turnstiles were counting down, and some reset to 0 at seemingly random times. To account for this we used the absolute value of the difference, and any values that were abnormally large we reset to 0 (since this is counting each individual turnstile, it is unlikely that one turnstile would have more than 10000 entries in four hours). We also set the value to 0 anytime the turnstile changed in the dataframe –taking the difference in values between two different turnstiles doesn’t make sense.
deffind_deltas(df):#creates two new columns, from the difference on the entries and exits columndf['delta_entry']=abs(df.ENTRIES.diff())df['delta_exit']=abs(df.EXITS.diff())foriinrange(0,df.index.max()):#if (df.iloc[i,6]==start_date) & (df.iloc[i,7]== '00:00:00'):if(df.iloc[i,2]!=df.iloc[i-1,2])|(i==0):df.loc[i,'delta_entry']=0df.loc[i,'delta_exit']=0if(df.loc[i,'delta_exit']>10000):df.loc[i,'delta_exit']=0ifdf.loc[i,'delta_entry']>10000:df.loc[i,'delta_entry']=0find_deltas(df)
One more thing, let’s add the entry and exit counts to get the total traffic:
df['TRAFFIC']=df['delta_entry']+df['delta_exit']
Data Exploration
Now that the tedious work of cleaning and managing the data is done, let’s see what the five busiest stations were by total traffic:
This code groups the data by station as well as hour bin (four hour intervals) and day of week. We’ll show the entries and exits but sort by total traffic.
STATION
hourbin
DOF
delta_entry
delta_exit
TRAFFIC
34 ST-PENN STA
(16, 20]
WED
276,241
344,637
620,878
TUE
268,276
348,503
616,779
THU
258,329
339,546
597,875
MON
256,919
329,947
586,866
FRI
249,860
308,534
558,394
Not surprisingly, the busiest times are during the evening rush, on weekdays, at Penn Station.